类ChatGPT聊天应用效果实现
最近要在产品中加入一个智能助手的功能,后端对接ChatGPT,本文整理一下整个开发过程中用到的技术点,主要是SSE流式数据和前端如何实现打字机的效果
参考
SSE服务端
SSE(Server-Sent Events,服务器发送事件)是一种允许服务器向浏览器推送数据的技术,它基于HTTP协议并使用单向通信模型。
SSE的工作原理是在浏览器发出HTTP请求之后,服务器保持连接,持续发送数据给客户端。这种技术常用于需要实时更新的应用,比如新闻推送、实时股票数据、聊天等。
SSE的特点比较明显
- 单向通信:服务器主动向客户端发送数据,但客户端不能向服务器发送数据。
- 基于HTTP协议:它使用了标准的HTTP协议,客户端通过长时间保持的HTTP连接接收数据。
- 自动重连:如果连接中断,浏览器会自动重新连接到服务器。
- 轻量级:相比WebSocket,SSE更加轻量,适合对实时性要求较低的场景。
目前主流的AI 文生文工具,基本都采用SSE作为基础的推送技术
- 相较于非流式接口等待很长时间然后输出一长段文字,SSE可以更快地展示大模型生成的少量文字,用户体验更好
- 由于不需要客户端频繁发送消息,因此不需要Websocket等长连接,节约服务器性能
接下来将演示使用NodeJS实现SSE应用的过程。
express实现SSE
首先创建一个express应用
const express = require('express');
const bodyParser = require('body-parser');
const cors = require('cors');
const app = express();
app.use(bodyParser.json()); // 解析 application/json 类型的数据
app.use(bodyParser.urlencoded({ extended: true })); // 解析 application/x-www-form-urlencoded 类型的数据
app.use(cors());
app.listen(3000, () => {
console.log('Express SSE server running on http://localhost:3000');
});然后定义一个路由接口
app.get('/chat', chat);
app.post('/chat', chat);
async function chat(req, res){
res.setHeader('Content-Type', 'text/event-stream');
res.setHeader('Cache-Control', 'no-cache');
res.setHeader('Connection', 'keep-alive');
const { messages = [] } = req.body; // 获取POST请求中的JSON数据
createIntervalStream(res)
}
function createIntervalStream(res) {
let cnt = 0
const timer = setInterval(() => {
if (cnt < 10) {
res.write(`data: this content is ${JSON.stringify(cnt++)}\n\n`);
} else {
clearInterval(timer)
}
}, 200)
}这样,当访问http://localhost:3000/chat的时候,就可以看见页面上每隔200ms打印了内容。
SSE的核心就在于Content-Type:text/event-stream这个响应头,主流浏览器都支持解析这个响应头。
查看控制台,可以发现这个请求多了一个EventStream的面板。
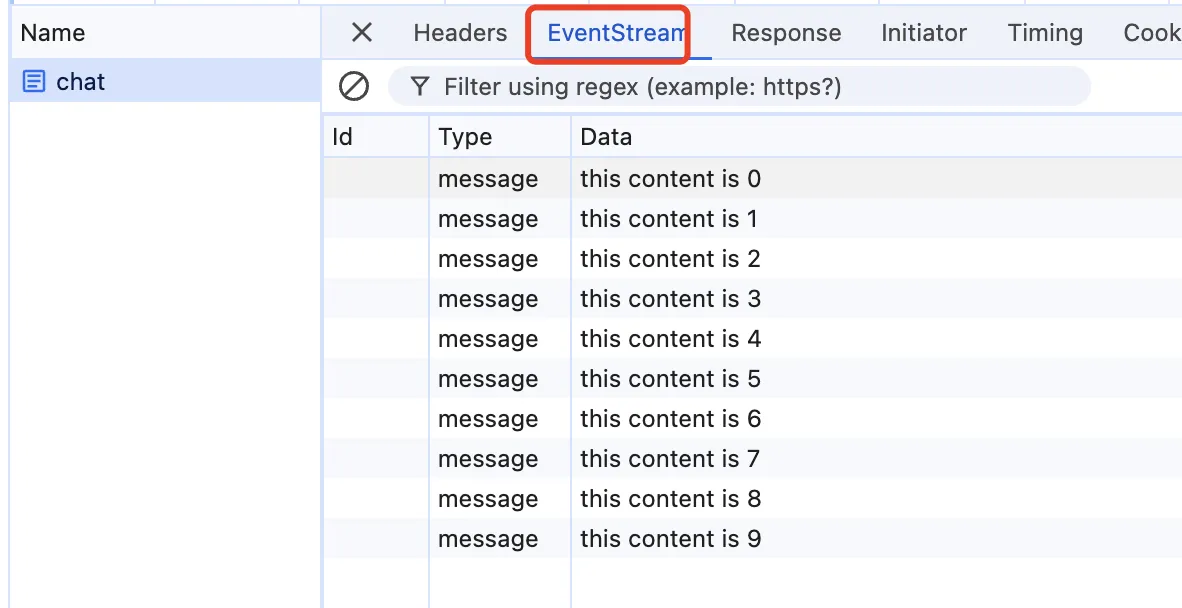
SSE响应规范
在上面的代码中,响应的是一个有固定格式的字符串。
res.write(`data: this content is ${JSON.stringify(cnt++)}\n\n`);根据HTML规范中的SSE章节,每条SSE消息由一系列以换行符(\n 或 \r\n)分隔的字段组成,最后以一个空行(即两个换行符)结束。每个字段由字段名、冒号和可选的空格后跟字段值组成。
以下是SSE响应中常见的字段:
data:实际发送给客户端的数据内容。每条消息至少需要一个data字段。id:消息的唯一标识符,客户端可以使用它来恢复断开的连接。event:自定义事件的名称,用于在客户端监听特定事件。retry:建议客户端在连接断开后重新连接的时间(以毫秒为单位)。
因此,如果是发送的内容里面(即data: 之后的内容)本身有换行符等保留符号时,可能会造成解析错误,因此建议对于需要传输的内容都进行编码,在客户端都进行解码。上面的代码使用了JSON.stringify进行编码,因此客户端需要使用JSON.parse解码,后文都使用这个逻辑。
模拟markdown
上面演示了最基础的SSE服务端的工作,实际上我们也可以模拟chatGPT的返回,或者是直接调用OpenAI的接口
在默认情况下,chatGPT会返回markdown形式的内容,前端会通过makdown-it等工具在运行时将md内容转成html内容,下面是一个mock接口,读取一个md文件,然后将内容通过SSE的形式返回
切换这个mock接口,只需要将路由接口中的createIntervalStream替换为createContentStream调用即可
function createContentStream(res) {
const filePath = path.join(__dirname, 'mock.md');
fs.readFile(filePath, 'utf-8', (err, data) => {
if (err) {
res.end();
return;
}
let index = 0;
const LEN = 1
const intervalId = setInterval(() => {
if (index >= data.length) {
clearInterval(intervalId);
res.end();
return;
}
let chunk = data.slice(index, index + LEN);
res.write(`data: ${JSON.stringify(chunk)}\n\n`);
index += LEN;
}, 20);
});
}真实聊天API调用
如果自己本身有OpenAI的API秘钥,也可以直接调用。如果没有但是也想体验真实的问答服务,可以使用Kimi等平替,其服务适配了OpenAI相关的数据结构
const OpenAI = require("openai")
const client = new OpenAI({
apiKey: "xxx", // 在这里将 MOONSHOT_API_KEY 替换为你从 Kimi 开放平台申请的 API Key
baseURL: "https://api.moonshot.cn/v1",
})
async function createKimiChatStream(res, messages) {
const stream = await client.chat.completions.create({
model: "moonshot-v1-8k",
messages: messages,
temperature: 0.3,
stream: true,
})
for await (chunk of stream) {
// 在这里,每个 chunk 的结构都与之前的 completion 相似,但 message 字段被替换成了 delta 字段
try {
const delta = chunk.choices[0].delta // <-- message 字段被替换成了 delta 字段
if (delta.content) {
res.write(`data: ${JSON.stringify(delta.content)}\n\n`);
}
} catch (e) {
console.log('chunk error:', e)
}
}
res.end();
}切换这个真实聊天接口,只需要将路由接口中的createIntervalStream替换为createKimiChatStream调用即可
SSE客户端
EventSource
在客户端,通常用JavaScript的EventSource对象来处理SSE:
const eventSource = new EventSource('server-url');
eventSource.onmessage = function(event) {
console.log('Data from server:', event.data);
};
eventSource.onerror = function(error) {
console.error('Error occurred:', error);
};EventSource本身只提供了基础的通信功能,对于比较复杂的应用而言,可以使用社区较成熟的开源库,比如@microsoft/fetch-event-source等
import { fetchEventSource } from '@microsoft/fetch-event-source'
function chat(){
fetchEventSource('http://localhost:3000/chat', {
method: 'POST',
async onopen(response) {
// 建立连接
},
onmessage: (event) => {
if (!event.data) return
// 约定所有内容均进行JSON.stringify处理,方便原样输出`\n`等字符
hooks.onMessage(JSON.parse(event.data))
},
onclose: () => {
hooks.onClose()
},
onerror(err) {
console.error('onerror:', err)
return null // 不重试
},
})
}这样,就可以在点击发送按钮的时候,发送请求,然后接收服务端推送过来的数据,再渲染到页面上了。
打字机效果
在调用实际接口的过程中,大模型的返回并不是像mock数据那样的定时器以恒定的频率返回,但在渲染时,我们希望以比较平稳的速度渲染字符,类似于打字机逐字输出的效果,这样用户体验比较好。
要实现这个效果,可以通过一个缓冲队列来实现,
- 在
EventSource的onmessage接收到消息时入队 - 开启一个定时器,以平稳的速度将队列里面的文字逐个展示到页面上
- 如果队列为空,但SSE还没有关闭,说明大模型那边卡住了,还没有输出内容,可以展示loading或者提示,或者执行超时流程
- SSE关闭,队列消息消费完毕,本轮会话结束,可以开启下一轮会话
首先实现一个打字机的接口,包含start开启定时器、enqueue消息入队列、stop关闭定时器三个接口
function createTypeWriter(onReceiveChar: (ch: string) => void) {
let queue: string[] = []
let timer: ReturnType<typeof setTimeout>
function calcSpeed() {
const speed = 2000 / queue.length
return Math.min(speed, 200)
}
function enqueue(str: string) {
str && queue.push(...(str.split('')))
}
function dequeue() {
if (queue.length) {
const ch = queue.shift()
onReceiveChar(ch as string)
}
}
function start() {
const loop = () => {
timer = setTimeout(work, calcSpeed())
}
const work = () => {
dequeue()
loop()
}
loop()
}
function stop() {
clearTimeout(timer)
queue = []
}
return {
enqueue,
start,
stop,
}
}onReceiveChar是出队列的回调函数,用于执行UI渲染等逻辑。
消息列表
消息列表中包含了用户的输入和GPT输出,通过一个role字段区分。
interface GPTMessageItem {
role: string
content: string
}在多轮对话中,实际上是通过一个post请求,将历史消息列表作为请求体提交来实现的,看起来实现了类似对话的效果,但本质上是:客户端提交->服务端SSE返回->客户端继续提交->服务端SSE返回的过程
下面是添加了消息列表等逻辑之后的完整Hooks实现
export function useGpt() {
const renderingText = ref('')
const chatting = ref(false)
const msgList = ref<GPTMessageItem[]>([])
function onReceiveChar(ch: string) {
renderingText.value += ch || ''
}
async function submitChat (prompt: string){
if (chatting.value) return
const { enqueue, start, stop } = createTypeWriter(onReceiveChar)
const messages = [
...msgList.value,
{ role: 'user', content: prompt },
] as GPTMessageItem[]
chatting.value = true
msgList.value.push({
role: 'user',
content: prompt,
})
await fetchEventSource('http://localhost:3000/chat', {
method: 'POST',
headers: {
'Authorization': 'Bearer your-token',
'Content-Type': 'application/json',
},
body: JSON.stringify({
model: 'gpt-3.5-turbo',
messages,
stream: true,
}),
async onopen(response) {
if (response.ok && response.headers.get('content-type') === 'text/event-stream') {
start()
console.log('Connected to SSE stream')
} else {
console.error('Connection failed')
}
},
onmessage: (event) => {
if (!event.data) return
// 约定所有内容均进行JSON.stringify处理,方便原样输出`\n`等字符
const text= JSON.parse(event.data)
enqueue(text)
},
onclose: () => {
stop()
chatting.value = false
msgList.value.push({
role: 'system',
content: renderingText.value,
})
renderingText.value = ''
},
onerror(err) {
console.error('onerror:', err)
return null // 不重试
},
})
}
return {
renderingText,
chatting,
msgList,
submitChat,
}
}在页面上,根据msgList进行渲染即可,renderingText和chatting主要是用来处理当前正在返回的这条消息,通过打字机的效果呈现出来
<MsgItem v-for="(msg, index) in msgList" :key="index" :msg="msg" />
<MsgItem v-if="chatting" :msg="{role: 'system', content: streamingText}" />打字机还需要展示一个光标闪烁的效果,这个光标应该位于文本的最后面,可以通过CSS伪类结合最后一个节点的形式实现,这里不再展开。
小结
本文总结了常规聊天式AI的开发技术要点,主要是
- 服务端如何返回SSE流式数据
- 前端通过一个缓冲队列,消费流式数据返回的字符,实现打字机效果
你要请我喝一杯奶茶?
版权声明:自由转载-非商用-保持署名和原文链接。
本站文章均为本人原创,参考文章我都会在文中进行声明,也请您转载时附上署名。
