前端字体反爬原理
最近研究了一些前端反爬的技术方案,感觉字体反爬还是挺有意思的,决定记录一下。
参考
效果
以某个招聘网站的工作列表为例,用户在界面上看到的是如下界面,阅读起来没有任何障碍
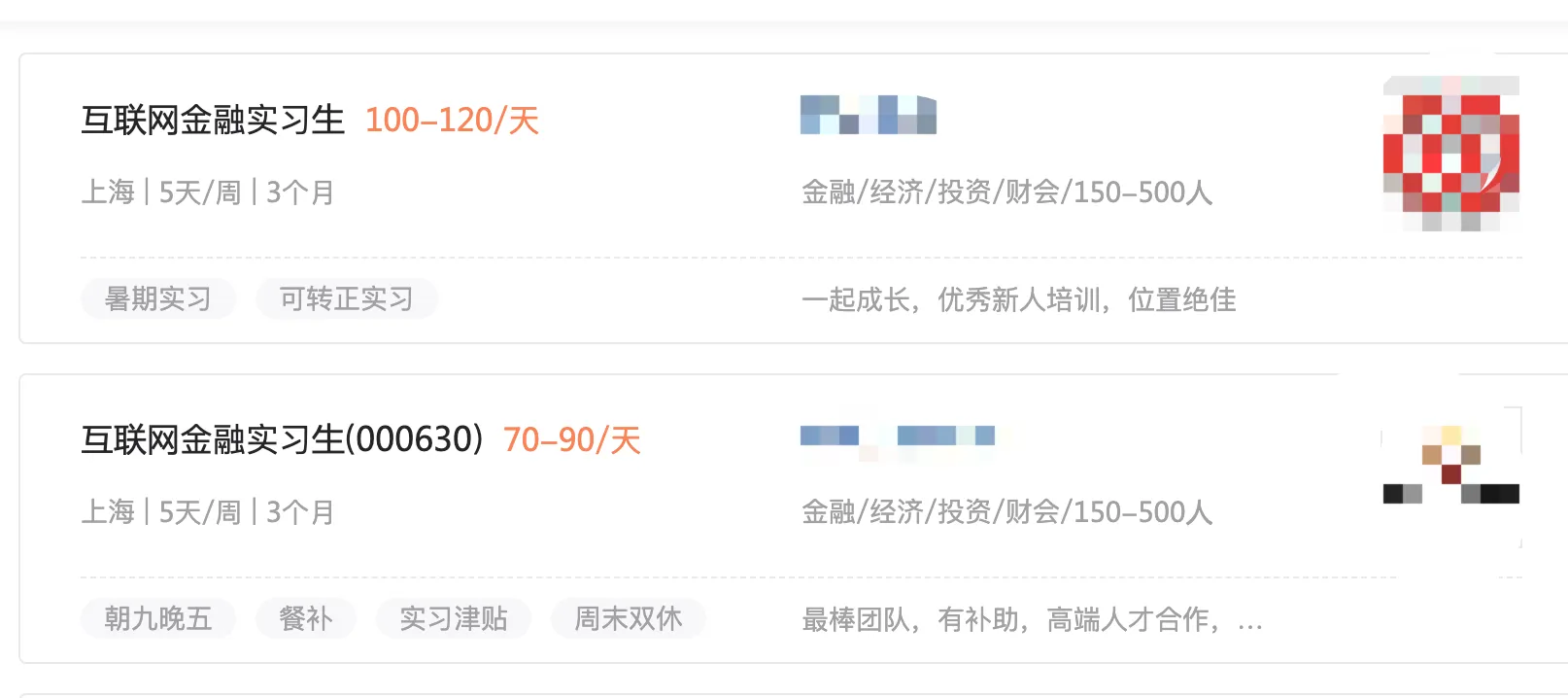
而打开控制台,可以看到部分敏感信息比如岗位名称、薪资待遇等,实际上并不是标准的字体,而是一串编码
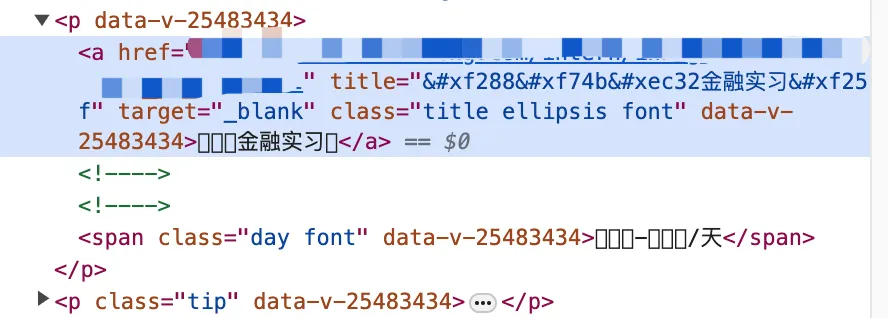
比如“互联网金融实习生”对应内容是“金融实习”。
观察一下这段内容,可以发现他们实际上是有规律的,即ʈ对应了“互”这个字,对应了联这个字,以此类推,不难看出这些编码实际上是一种特殊的字体(对应的标签上还有font这个特殊类,指定了特殊的font-family
因此,通过一种特殊的自定义字体,而对于普通用户而言,在页面上还是可以看见正常内容,完全不会受到影响;而直接抓取HTML,却解析出原本的岗位名称了,这样就达到了反爬的目的。
接下来解释一下这个方法的实现原理,以及一些优缺点和注意事项。
字体反爬原理
css支持通过@font-face引入自定义字体
@font-face {
font-family: xxx_font_name;
src: url(xxx/font.woff);
}定义好的字体集xxx_font_name就可以在font-family中使用。前端开发中,接触到的自定义字体更常见于字体图标上面,比较成功的如iconfont等,字体图标其实就是一种特殊用法的自定义字体。
在计算机系统中每个字符都有一个对应的 Unicode 编码,而每一个字符在操作系统中就是一个矢量图形,自定义字体文件的作用,就是用来规定这些编码对应什么样的图形。把每一个字符都想象成一个图片,就容易理解自定义字体的原理了。
所以,要知道金融实习对应的完整内容,只需要找到具体的字体图标,找到对应的编码就行。
首先找到对应的自定义字体文件

然后下载字体文件

最后随便找到一个在线字体解析网站,比如这个iconfont-preview,将字体文件丢进去,就可以看到每个编码对应的实际内容了
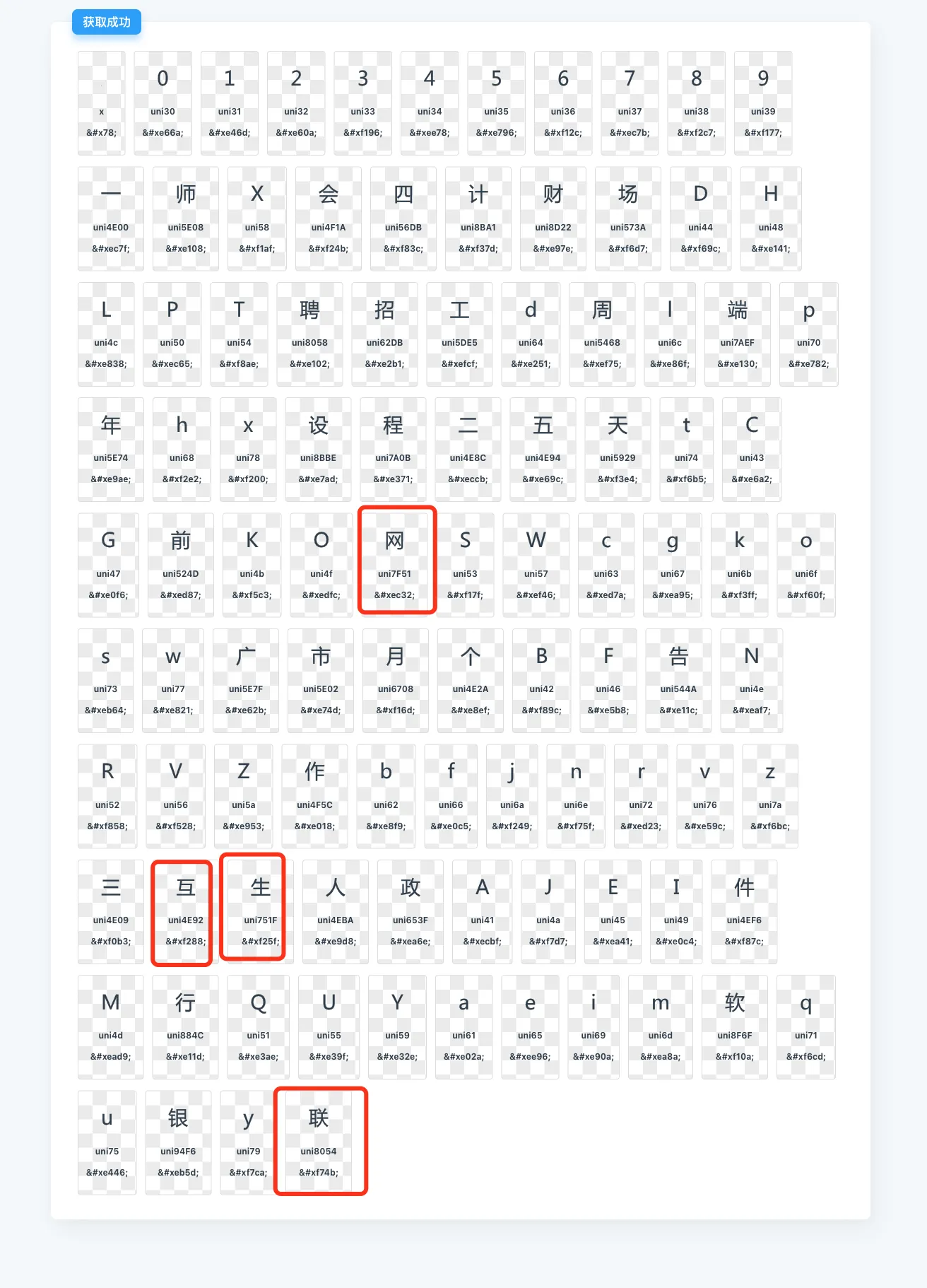
这个工作需要耗费一定的时间,即使找到了编码对应的字符含义,也无法将它跟常规的字符内容关联起来,比如对应的内容是“互”,但这个截图里面找到的内容,只是一个长得跟“互”一样的图片,如果要将这个图片通过程序识别成“互”这个字,还需要引入图像识别更工具
因此,字体反爬从效果上来看,还是非常成功的:不影响正常用户使用,但逆向解析出原始内容会非常麻烦。
从上面的逆向解析过程中,也可以看出字体反爬的技术原理。
首先,生成特定的字体集,在这个过程中要创建一个自定义的“互”,可以将其的编码与常规字符“互”的映射保存起来
const fontMap = {
"互": "",
// ... 其他很多字体
}然后,将要展示的内容替换成对应的字体编码
export function encodeString(str: string) {
let ans = ''
for (const ch of str) {
ans += fontMap[ch] || ch
}
return ans
}
const rawContent = '互联网金融实习生'
const content = encodeString(rawContent) // 金融实习最后,再将得到的编码后的内容嵌入到HTML中返回给浏览器渲染就可以了。
注意事项
自定义字体反爬,在实际生产中还有一些注意事项。
多套字体
根据上面介绍的原理可以看出,要解析自定义字体,只需要找到原始的字体集,然后将编码和文字一一对应起来即可。
虽然这个过程比较耗时,但是借助AI或者多人工的方式,逆向得到编码和原始字符的含义也不是一件不能实现的事情。一旦这个这个映射,再借助这个字体反爬就没有意义了。
为了解决这个问题,在实际生产中,会创建多套自定义字体,根据随机算法在某次请求时,随机返回使用的某套字体。比如同时准备10套字体,在第一次请求时返回的时字体A,而在第二次请求的时候返回的是字体B。
这样即使通过一定的工作量得到了这10套自己的所有映射,也无法判断某次返回具体使用的是哪一套字体,也就不能通过这个映射解析内容,这样,爬虫的效率就会大大降低,也就打到了反爬的目的。
控制字体数量
理论上,可以对站点所有的内容都进行字体编码,这样每一个字符都是特殊的编码,可以达到内容完全反爬的效果。
但是为每个字符都创建自定义字体,最后创建的字体集就会非常庞大(数M至数十M),会影响页面的渲染。其次,为了反爬效果,还需要准备多套字体集,而创建一套新的字体,成本也是比较高的。
因此在实际生产中,一般只将少数用的比较频繁的字符、数字等进行自定义编码。这样就只需要引入一个几十k的字体文件,就可以对大多数数据进行编码反爬了。
至于具体讲那些字符打包进自定义字体集中,则是一个经验问题,大概来说,选择项目数据中最常用的前50个字一般是没有什么问题的。
SEO
由于自定义字体会让正常的爬虫也不知道具体的内容,因此可能会影响SEO效果。
本质上,前端反爬手段都会影响SEO,毕竟SEO也是靠搜索引擎的爬虫来收录的。如果要反爬的同时又不影响SEO,貌似只有从请求IP等服务器手段来限制了。
小结
字体反爬的原理是:通过自定义字体集,将核心内容替换为字体集中的编码,这样浏览器中可以正常展示,但抓取下来的数据是字体编码,只有手动解析逆向的文本。
但是,如果数据有价值,那么有数据,就有爬虫;有爬虫,就有 反爬虫;有反爬虫,就有逆向反爬虫...
由于现在图像识字OCR等技术已经非常成熟了,即使在字体反爬做到了极致,只要数据是展示在界面上给用户看的,那就可以绕开这个自定义字体,直接通过截图等方式拿到内容。
最好的反爬方法,感觉还是通过法务等技术层面之外的手段来实现。作为开发者,我们只有尽量让爬虫的成本变高,让爬虫获得的收益小于这个成本。
你要请我喝一杯奶茶?
版权声明:自由转载-非商用-保持署名和原文链接。
本站文章均为本人原创,参考文章我都会在文中进行声明,也请您转载时附上署名。
