反思我写过的烂代码
这篇博客的草稿是17年10月15号创建的了,每次写了些东西打算发布的时候,总觉得还差了什么。现在写了四五年代码了,经手了很多项目,有简单的活动页面,也有很复杂的业务逻辑,是时候反思一下我写过的烂代码了。
下面是正文。
感觉自己已经写了不少代码了,但每次回头看前一两个月的代码,却总觉得烂的不行。起初我以为是我没有掌握高效率编程的姿势,比如单元测试、断点调试等技术。最近看了一些书,静下来想了想:要避免写烂代码这个问题,不在于你掌握了多少编程技术,不在于你了解多少语言特性,一切都应该从“你怎么看待写代码这项工作”开始。
参考:
- 编程的智慧-王垠
- state-of-the-art-shitcode,垃圾代码书写准则
- 关于烂代码的那些事,写的非常好
- bug是怎样产生的
- 理想的应用框架,很有意思
什么是烂代码
每个人的性格、技术水平和工作经历都不一样,看待“好代码与烂代码”的标准也各不相同,下图是一张比较出名的关于在Code Review中评判代码质量的图片
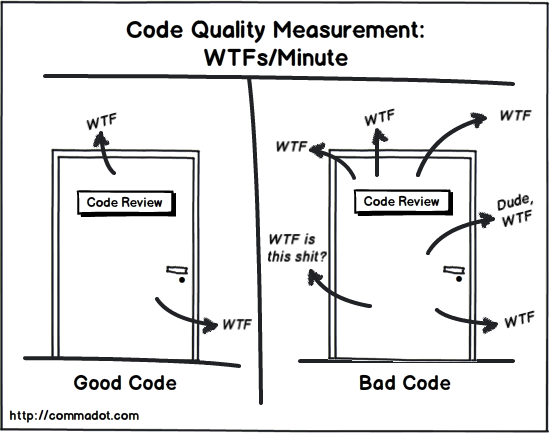
逻辑混乱,实现复杂
代码可读性很差,主要包括
- 各种魔法数字、奇葩变量名
- 没有注释或注释含义模糊,经常词不达意,一问才知道是忘记更新注释了
- 混乱的代码结构,各种条件判断、面条式代码、回调嵌套
- 冗余复杂的实现,会“茴字的四种写法”等秀技操作并不会帮助整个系统有质的飞越
- 不简洁,由于个人水平的限制,无法写出简洁优雅的代码;亦或者是对系统里面使用的库与框架不熟悉,不知道原本就有类似的功能,自己实现了一套比较复杂的封装
基本上就是我第一年写代码的状态,当时jQuery还比较流行,满页面都是$xxx.parent.parent.find(xx).nextSiblings之类的代码。代码是用来描述逻辑的,而混乱的代码是Bug源头。
现在借助各种IDE或lint工具,基本上可以规避各种奇奇怪怪的写法,保证代码风格的统一。
不够健壮,难以测试
我们无法预料产品会如何变化,也无法预料用户产品使用方式,当程序没有覆盖到所有的场景时,就可能会出现bug
- 各种没有考虑到的边界情况、外部依赖异常,隔三差五的报错或崩溃
- 修复了一个bug,又引入了10个bug
- 缺少异常处理,难以定位bug
错误处理,最基本的就是使用try...catch,然后在历史项目中也见到过很多错误使用的代码。
try...catch并不是让我们把错误吞掉,而是为了在系统不会因为我们编码时未能覆盖的情况导致崩溃。没有明显的错误并不代表么有错误,反之,如果将一个错误静默地catch处理掉,我们就无法获取系统真实的问题了。
健壮性评判的一个标准就是单元测试的覆盖率:如果害怕出bug,那就应该让bug早点出现,最简单的方法就是进行测试。
单元测试的好处大家都知道,但我接手过的项目,除了少部分基础工具库和组件库项目外,其他都很少见到测试用例;甚至是我自己目前负责的项目,也经常是在事后才去补上一些基础的测试用例,覆盖率更是低的可怜。
一方面是开发任务比较紧,来不及提前编写测试用例;
另外一方面是之前的历史代码有许多地方包含全局变量或外部依赖,很难进行单元测试
// 要测试下面这个方法,还需要对外部变量name进行mock
function test(){
return `hello ${name}`
}
// 相反,如果函数的逻辑只依赖于参数,则很容易进行测试
function test2(name){
return `hello ${name}`
}最简单的判断是:依赖越多,测试越难。因此,还需要保证良好的模块划分,避免循环依赖,这就涉及到另外一个话题:如何对项目代码进行分层管理
难以维护
“维护”的含义包括了修复旧代码、开发新功能,“难以维护”的含义就是很难修改旧代码、很难添加新功能。烂代码所有的特点最后带来的影响都是难以维护,而易于维护的代码,需要满足下面几个要求:
- 流程清晰,不论是从结果(如视图展示)倒推,还是从入口(初始化应用)顺推,能让维护者明白整个代码的流程
- 容易找到改动的地方,从一个1000行的函数中找到某个if判断然后修改,想想都头疼
- 维护者能很清晰的评估本次改动的的修改范围,不会有遗漏的地方
- 维护者能很清晰的评估本次改动的的影响范围,不会产生意料之外的结果
- 有良好的代码风格,每次修改之后仍旧能保持统一的风格和可维护性
- 易于扩展,方便添加功能
很多代码在最初的版本,往往是清晰可查的,随着功能的迭代、需求的变化,就逐渐偏离了原本的设计,最后成为了烂代码。为什么我的代码会逐渐变烂呢?这也是本文主要思考和探究的问题
刚入行的时候就听到了一个常用来调侃产品的段子:这个需求很简单,怎么实现我不管。
站在开发的角度来看:产品不懂技术,他根本不知道我的代码里面xxx不是这样设计的,看起来实现这个需求只需要xxx,实际上我要改很多地方,还需要回归balabala。
站在产品的角度来看:整个应用的功能我是最熟悉的,按照之前的产品设计,这个改动符合逻辑,应该很快就能实现。
那么问题来了:到底是哪里出了问题?
最近我开发完某个功能之后,在本地开发环境向产品演示并确认整个功能流程,这个时候我突然产生了一些困惑:
为啥我开发花了一天,演示只需要花费两三分钟呢?毕竟这个功能又不像“向地址栏输入url后,展示整个页面”这种演示只需要两秒钟,实现却无比庞大的功能。
我好像有点明白了,对于这个需求
- 开发需要一天,确实很麻烦
- 功能演示只需要两分钟,也没啥大的修改,确实挺简单的
那么,为什么产品理解的简单需求,开发却需要花费很多的时间来修改?是不是代码设计跟产品设计有出入呢?
换个角度,现在问题就变成了:为什么我们编写的代码,维护起来却这么麻烦呢?有没有一种能够完全还原产品设计的开发方式,可以很轻松地添加、修改各种功能呢?
结构化编程的习惯
在我刚开始学习写代码的时候,对于自己没有处理问题的头绪而焦躁不已,甚至还去看了看《像程序员一样思考》之类的书(当然这本书本身还是不错的)。后来学到了一种最简单的方法:想好代码要做什么,先写xx,再写xx,这样就可以了。
编程的逻辑,实际上是对于某个产品需求执行具体过程的描述,在期间可能还需要使用一些条件或循环,直到实现最终目的。
在软件工程的某个历史节点,随着需求越来越复杂,大佬们提出了结构化编程,提倡只使用循序、选择和重复这三种结构来表达逻辑,同时废弃 Goto;这是非常伟大的创举,仅用这三种结构,就能实现绝大部分逻辑。
结构化编程要求我们
- 如果想要理清某段代码的逻辑,需要从入口开始查看
- 如果想要增加或删除某个功能,也需要按结构化的顺序找到逻辑在代码中位置,然后进行修改;
- 而每次改动,都会对代码的结构造成影响
而实际的业务流程可能会很长,甚至出现跨项目、多人员共同维护,常见如客户端 —> 服务端 -> RPC服务 -> 服务端 -> 客户端,我们面前看见的代码可能只是冰山一角,这导致理清整个代码流程十分困难,造成“只在此山中,云深不知处”无从下手的局面。
下面用伪代码描述“做麻婆豆腐”的流程
准备豆腐和豆瓣酱()
开火()
放油()
炒()
装盘()看起来很流程很清晰,然后加一些判断,处理没有食材、以及味道咸淡的判断
准备豆腐和豆瓣酱()
+ if 没有材料 then 购买食材()
开火()
放油()
炒()
while 味道不好:
+ if 淡了 then 放盐
+ elif 咸了 then 放豆腐
+ 炒()
装盘()看起来勉强也能看得懂,直到我们逐渐向里面添加一些特殊的逻辑
# 特殊处理小明
+ if 小明 then 准备豆腐和郫县豆瓣酱()
+ else 准备豆腐和豆瓣酱()随着这种改动逐渐增加,原本的线性结构已经淹没在大大小小的逻辑里面了。虽然这段代码也能满足业务要求,但我们需要花费比前一次改动更长的时间来查找需要修改的地方,同时这一次改动带来的影响也会叠加到下一次。
这也是为什么一个原本很简洁的功能,在陆陆续续添加一些新功能和特殊逻辑之后,就变得很难维护了。
堆积的技术债务
我们的每段代码都是在某种特定场景下编写的:可能是有充足的排期、全面的测试;也可能是临时hack,火急火燎地处理某个特殊问题;也可能是当时当时心情愉悦、亦或是工作不在状态。我相信绝大部分同行都有最基本的职业道德,至少在我的职业生涯中,还没有见到过由于发泄、报复或其他私人原因故意写一堆bug的情况。
但由于各种各样的原因,在某些时候明知道代码这样写并不优雅,但他能完成需求,所以最后还是提交了,最多写下个Todo用于心里安慰。这就欠下了一份技术债务,而技术债务是很难偿还的,这些代码静静地躺在某个commit中,等待着被重构或下线,结束它的使命
对于历史悠久的技术债务,如果害怕修改导致系统崩溃,而放任烂代码继续存活在系统中,久而久之,欠下的技术债务就会越来越多。
“只要我不做,我就不会犯错,既然这段代码在好好的运行,为啥还要去改他呢?”,这种观念也会影响我们偿还技术债务的心态。
我向来是不太抗拒去修改旧代码的,甚至于对于自己编写的烂代码有一种耻辱感,看见了就会想着优化,但个人的精力总归有限的,有的技术债务需要耗费很多的时间,对业务而言却没有什么改变。
所以,大部分业务代码都是随着时间实例,技术债务越来越多,体积逐渐增加,越来越难添加新功能,也越容易崩溃。到最后可能只剩下了“重构”这条路,然而重构并不是万能药,往往会由于人力、时间、收益等因素夭折~
记得之前看见过一种关于让代码随着维护越改越好的架构的思考,但是就“技术债务”这一点来看,如果单纯依赖架构来限制程序员不留下技术债务,应该是很难实现的吧。唯一能做的,大概就是祈求之前的同事少留点坑,同时要求自己给后面的同事少留点坑吧。
对旧代码的信任感
世界上最简洁易懂的代码,是自己刚写出来的代码。 世界上最烂的代码,就是自己一年前写出来的代码。
关于旧代码,我们经常能听到:“这段代码谁写的,也太垃圾了吧”之类的抱怨,就好似开发者和维护者的立场天然对立一样,当然也可能是一年前的自己和现在的自己是对立的哈哈。
对历史代码的不信任,也会导致代码的设计被破坏,相当于在摇摇欲坠的门框上又踹上一脚。毫无疑问,DRY是非常正确的,我们将其当作教条,并唾弃重复的代码。但是在维护一个遗留下来的项目时,我们却可能会害怕重用之前的代码,
- 觉得之前的代码写的看不懂,没法维护了,得重新写一个
- 不知道之前的这段代码被哪些地方依赖,与其害怕改出毛病,不如重新写一个
然后只能加上了一堆至少自己能明白的代码。但如果这段代码还能被后面的人维护,他们大概率也不会信任我们的代码了,周而复始。
是什么原因造成这种信任感的缺失呢?最主要的原因是我们不知道这段编写旧代码的具体场景了。
从维护者的角度来看,如果我们已经不清楚或者已经忘记了相关的逻辑,除非从头深入研究它们,否则我们很难理清这段旧代码的上下文。我之前修改过一段我认为很烂的旧代码,快改完的时候才发现,“哦,原来他这里是因为xx才需要要这样写”,然后又把代码给回滚回去了。
测试用例好像是一种维持信任感的有效方式,如果有测试用例,我们在修改之后还能跑一遍看看哪些地方不会通过,这样就能定位我们改动造成的影响(如果覆盖率足够高),但不幸的是,很多历史代码可能都没有测试用例。
虽然CSS算不上编程语言,但用来举例证明这种不信任感还是不错的。
在没有css modules或者css scoped之前,整个应用的样式都是全局作用域的,假设我们现在要实现一个.title的类,就需要去历史的样式表中全局搜索是不是已经存在.title这个类了,否则可能会出现样式冲突、或者影响其他样式的地方。
为了偷懒,我们可以借助CSS 权重值计算规则进行样式覆盖,加个!important或者再加个标签.xxx .title之类的覆盖一下,以至于社区出现各种诸如BEM命名规则的方案,来解决这种情况。
此外包括zIndex等层级属性,也存在类似的信任问题,为了避免我的弹窗被代码角落的某个样式影响,直接写9999...续上接N个9,不管后面代码的死活。
蹩脚的封装
我们无法预知代码的改动,但可以编写方便后续维护的代码,如何从维护者的角度衡量”易于维护“的代码呢?
在过去很长一段时间内,我都认为:只要改动的地方少,代码就“易于维护”。基于这个念头,我在编码时进行了很多刻意的尝试,比如
- 减少变量的重复,通过配置文件管理全局变量
- 减少代码的重复,封装函数、封装模块
- 减少逻辑的重复,封装组件
减少改动最好的办法就是将统一的逻辑封装起来,封装的核心概念是将系统中经常变化的部分和稳定的部分隔离,按照设想,封装的作用
- 将相同功能逻辑的代码块从物理结构上限制在一起,方便查找,这样后续的改动修改的代码就会变少
- “每一个优雅的接口后面都有一个肮脏的实现”,维护者不需要关心肮脏的实现,也能写出好代码
- 封装能够减少全局变量和自由变量的使用,更容易测试
按照我的理解,封装就是为了复用代码,但后来却发现,往往在不知不觉中,封装就与”易于维护“的目的背道而驰,时不时需要修改原本已经封装好的代码,比如给函数再加个参数、给模块再暴露几个方法、给组件再加上一些prop,做一些额外的判断,再之后就会出现“改动少,并不代表影响的地方少”的情况,有的代码牵一发而动全身,继而需要修改预料之外的代码。
可见蹩脚的封装也是影响可维护性的诱因只一。接下来讨论一下在使用封装的过程中遇见的问题
强行封装
现在需要封装一个商品组件,我们有两种思路
- 一种是根据支持传入某些查询条件,组件先查询商品,再进行展示,相当于组件需要负责查询和展示
- 另一种是只接收一个商品参数,由调用方自己查询并传入商品,相当于组件只负责展示
为了代码复用,我大概率会使用第一种方式,把看起来比较通用的逻辑都给封装起来。而在某些需要直接传入商品的场景下,就得再暴露一个参数,同时判断有这个参数就不再请求查询接口了。
这种做法影响了我对封装的实践,可能会强行把一些看起来比较重复的逻辑(比如请求接口处理响应)封装起来,忽略了业务变化的影响。导致在不同的业务场景中,为了适配每个逻辑的特殊性,额外做一些if..else判断。
后来我才理解到,封装并不是从物理位置把代码拆分到不同的函数、类或文件中,而应该是从概念上,定义良好的输入和输出。
上面的示例中,展示的逻辑是不变的,变化的地方在于商品详情的获取方式,所以变化应该从不变的地方拆分出去。
对于要封装的代码,我们需要考虑变化的来源,先找到变化,这样才能确认哪些是可以封装在一起的。但是我们无法提前预估到所有的业务变化,也无法确保当前封装的通用逻辑日后是否会变化,究竟应该把哪些逻辑封装成在一起呢?
低廉的改动成本
在使用框架时,如果某个功能实现起来比较麻烦,我们想到的是如何实现这个功能,而不是如何修改底层框架来满足我们的需求。
举一个实际的例子,在移动端开发中,很多场景下会使用rem做屏幕适配,为了减少手动计算rem单位的时间,postcss社区提供了诸如postcss-px2rem的插件,该插件可以自动将样式表中的px计算并转为rem
但在某些场景下,我们希望某个或某些文件下面的样式不被转换,因此可以使用postcss-px2rem-exclude,这个插件允许我们指定exclude参数来忽略某些文件的单位自动转换
但如果我们如果需要在同一个样式表中,既能够将大部分px单位自动转换,又需要将少部分px单位保留(比如border),这时候上面的exclude就不能满足了。一种HACK的办法是使用PX(大写)来代替px
那么问题又来了,在webstrom等IDE中提供的快速代码格式化,可能会自动将PX转换成px,这就导致HACK方法失效,一种为了保留HACK的HACK方法是使用scss的@function,
// util.scss 要求不在这个文件中使用快速格式化!!
// 返回原始像素单位
@function PX($px) {
@return #{$px}PX
}虽然工具始终无法覆盖所有的应用场景,但我们会想方设法从外部来扩展功能,而不是想着修改postcss-px2rem插件来提供一个类似的功能。
可同样的情况到了我们项目里面,为什么就想着要去随便去修改已经封装的代码呢?比如随手加个参数,加个if判断之类的?
一方面原因是上面提到的,我们把可能会变化的业务进行了封装,诱导我们去修改已经封装的代码
另外一方面原因是:封装的代码是我们自己写的,不像其他框架或库里面的代码有天然隔离(比如前端项目放在node_modules里面),从结构化编程带来的惯性思维可能会导致我们下意识的去修改这些代码,就会导致封装更容易被破坏
有什么方法能约束我们不去修改封装的代码,或者提高修改的成本呢?
最简单的做法是单一职责,如果这段代码没有修改的必要,那我们就不会时时刻刻想着去修改他了
单一职责原则(Single Responsibility principle)要求开发人员编写的代码有且只有一个变更理由。如果一个类有多个变更理由,那么它就具有多个职责。如果我们有两个或多个原因去修改某一处代码(某个类、某个对象或方法),就表示这段代码违背了单一职责
破坏封装
封装的本意是将业务中变化的地方进行隔离,将不变的地方给封装起来,这就提供给我们一种可以快速修改代码的能力,只需要修改某一处,就会影响所有依赖,看起来对于添加通用功能很诱人,在快速迭代期间,我们往往受不了这种诱惑。
在这些行为下,我们很可能就会破坏封装原本的意义,将一些其他奇奇怪怪的功能引进来,最后的结果就是封装的逻辑不再通用。
归根到底,是我们没有清晰地区分职责,把“可能的变化"也给封装起来,这诱导我们去修改封装部分的代码。
目前有一个纯UI组件,它接收一个特定的数据结构config,然后展示出来就行了。目前有10个页面在使用,
现在多了一个需求:点击这个组件的时候需要上报数据,我们面临两个选择
- 在每个依赖于该组件的页面注册点击事件,处理上报逻辑
- 改10个页面太麻烦了,幸好将他封装成通用组件了,在组件内处理数据上报就行了
请先思考一下你会选择哪种做法?
假设我们选择了第二种做法,很显然,这次需求太简单了,评估一天的工时,花半个小时搞完,剩下的时间就可以摸鱼了
改动:我们在UI组件里面添加了数据上报的功能
这样这个组件就包含了两个功能:UI展示和埋点上报;当那些需要该组件进行展示UI时,就静默地带上了数据上报的功能,而这个功能可能并不是使用者希望的。
也许可以再添加一个prop,比如needReport之类的,用来控制使用者是否需要日志上报,显然这不是一个很好的做法。
改动:我们在UI组件增加了一个needReport的prop用来控制是否需要上报
假设现在系统中有15个使用这个UI组件的地方,其中10个需要额外进行日志上报,5个只需要进行UI展示
那么根据现在的设计,我们需要在10个地方传入:needReport="true",在5个地方传入:needReport="false",尽管可以通过设置prop默认值来省略部分值的传入,但毫无疑问,我们现在打破了组件的通用性,这个UI组件已经变得不再通用了!!!使用者需要知道这个组件有哪些功能,需要传入哪些参数来控制对应功能。
按照设计初衷,这个组件不是只接受一个config数据,然后展示出来就行了吗,事情为什么会变成这样?
不考虑先有UI组件、再有数据上报的客观时间顺序,我们为了强行把某些看起来比较重复的代码给封装起来,然后又为了满足每个地方特殊的逻辑,添加越来越多的参数和判断。
当需要修改旧代码时,我们应该先明白这种变化的产生的原因,这样才能确认应该把改动放在哪里,当前的改动是否是合理的。在旧代码里面添加新功能,除了影响旧代码,也会限制新代码。
假设能够进行时光倒流,我们在接到那个“数据上报”功能的时候,选择第一种方案呢?不修改旧代码,在每个依赖该组件的地方都写一遍数据上报的功能,这样显然也不合理。
像这种需要动态添加非组件逻辑相关功能的时候,也许可以使用装饰器来实现,封装一个待日志上报和UI展示的高阶组件怎么样?
没有什么问题是不能加一层中间件解决的,如果有,那么就再加一层
在不修改原代码的情况下动态扩展功能有下面几种方式
继承,在不修改父类的情况下扩展子类的功能
混合,直接扩展对象的方法,但是当对象使用了多个混合的时候,不容易追踪某个方法具体的来源,就像把水和墨水混在一起之后,我们就很难把他们分离出来了
装饰器或拦截器,在逻辑发生之前或之后调用,具有容易拆装的性质,缺点在于无法修改中间的逻辑
当然过度抽象和封装也存在一些问题,需要一层一层深入进去才知道整个组件的完整功能。
小结
就目前为止,我已经不太会可能写那些很初级的烂代码了,比如随便定义的全局变量、大段大段重复的代码,至于工作效率也还算凑合,拿到需求基本不会delay。此外这几年,也断断续续学习了SOLID原则,翻阅《代码大全》《设计模式》《重构》相关的书籍,并尝试在代码中进行优化。然而每当回头去看自己写的旧代码,仍旧会有一丝羞愧感,也会担心别人看见我的代码然后吐槽。我很清楚优雅代码的重要性,但在现实开发中,往往需要在各种情景做一些取舍和权衡。真的存在很优雅的代码吗?
现在,我已经深刻的体会到”软件开发没有银弹“这句话的含义,也不再追求完美的代码,代码本身是服务于业务的,满足业务比编写所谓“优雅代码”重要的多,但作为一个还有点追求的写代码的,少些一点被人鄙视的代码还是很有必要的,毕竟写代码是多么有意思的一件事情啊。
附:最近7天的写代码平均时间(包含工作任务和个人项目代码,主要的是自己的代码哈哈,最近的活比较少),来源waka统计
下笔之前本来有一堆想写的东西,翻来覆去改了很多次,却无法完全表达出自己的感受,只能草草结尾,后续不定期更新并继续反思。最后,尽自己所能,少些一点烂代码。
你要请我喝一杯奶茶?
版权声明:自由转载-非商用-保持署名和原文链接。
本站文章均为本人原创,参考文章我都会在文中进行声明,也请您转载时附上署名。
